はじめに
こんにちは!
機械とAIが繋がるスマートな製造現場を作っているEdgeCrossです。
前回の記事(【Inside AIoT】機械管理知能化のためのAIデータパイプライン(1) )では、AIデータパイプラインとは何か、なぜ必要なのか、また、どのように構成されているのかを説明しました。
今回は実際にこのようなデータパイプラインをEdgeCrossがどのように実装したのか、もう少し詳しく説明したいと思います。
EdgeCrossのデータパイプラインの実装方法
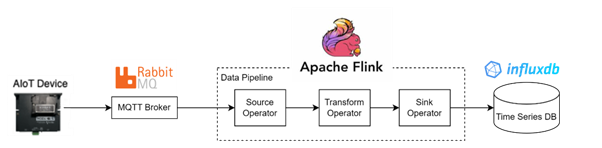
EdgeCrossのデータパイプラインは、図のように1. MQTT Broker、2.Data Pipeline、3.Time Series DBの大きく3つの要素で構成されています。MQTT BrokerはIoTデバイスからデータを収集し、Data PipelineはMQTT Brokerからデータを抽出、変換してTime Series DBに保存されるシステムです。
- 1. バッファリングとメッセージのキューイング
-
MQTTメッセージは、IoT機器で発生するたびにリアルタイムで送信されます。
このようなデータフローは、トラフィックの急増やネットワーク遅延などによって不規則になることがありますが、メッセージブローカーを使用すると、このようなメッセージをバッファリングしてキューイングし、より安定的にデータを送信することができます。 - 2. 信頼性と耐久性
-
メッセージブローカーはメッセージの転送を保証し、システム障害が発生した場合、メッセージを安全に保存し、復旧する機能を提供します。
RabbitMQはメッセージをディスクに保存し、Flinkや他のシステムの障害発生時にもデータ損失を防ぐことができます。 - 3. 弾力性
-
RabbitMQのようなメッセージブローカーは、ダウンストリームシステムの可用性に影響されず、独立して運営することができます。
例えば、Flinkアプリケーションがメンテナンスのために一時停止しても、RabbitMQは引き続きデータを受信・保存することができます。
MQTT Broker
MQTT Brokerを実装するためのツールを選択する過程で、私たちはこのような部分を考えました。
まず、データ収集を担当する部分は、データソースから送信される通信方式をサポートする必要があります。
前の記事で説明したように、EdgeCrossではMQTTを利用してデータを送信します。 そのため、MQTTをサポートするメッセージブローカーソフトウェアが必要でした。
メッセージブローカーの役割ができるソフトウェアの中でRabbitMQ, Mosquittoを検討しました。
Kafkaの場合、高いスループットと耐久性が長所ですが、MQTTプロトコルをサポートしていないため除外しました。
では、RabbitMQとMosquittoはどのようなソフトウェアが適しているのでしょうか? どちらもIoT通信のためのMQTTをサポートしていますが、若干の違いがあることに注目しました。
RabbitMQは、MQTT以外にも多様なプロトコルを提供し、クラスター構成を通じて高い可用性と拡張性を確保することができます。
また、メッセージキュー、耐久性のあるストレージ、転送確認などの機能を提供するため、高い信頼性を持っています。
Mosquittoは、MQTTに集中して設計され、軽くて効率的なメッセージブローカーです。
インストールやメンテナンスが楽で、様々なIoT機器との互換性もあります。
まとめると下記のように説明することができます。
- RabbitMQは、クラスター構成などの追加作業とリソース使用量が多いですが、安定的なメッセージングと拡張性、分散処理に適しています。
- Mosquittoは、MQTTに限っては速いメッセージ伝達、簡単なインストールやメンテナンスなど色んなメリットがありますが、小規模システムに適していると言えます。
EdgeCrossは、最終的にRabbitMQを選択しました。安定的なメッセージ配信と今後の規模拡張性が重要だと考えたからです。
さらに、データパイプラインを構築するために使用したFlinkとRabbitMQが組み合わせて使いやすいからです。
- Flinkは本質的に分散データ処理のために設計されたシステムですが、RabbitMQを使用することで、複数のFlinkインスタンスまたはクラスター間でメッセージを均等に分配することができ、処理能力を拡張するのに有利です。
また、Flinkが独自にRabbitMQのコネクタを提供しているため、追加開発なしでRabbitMQとFlink間の接続が可能です。
MQTT Broker
データパイプラインを構築するために、ある程度認知されているストリーム処理フレームワークを検討しました。
配信保証、耐障害性、状態管理など、ストリーム処理で重要な要素を中心に整理すると、各フレームワークの特徴を以下の表のように見ることができます。
| Flink | Spark | Storm | Kafka | |
| データ処理タイプ | ハイブリッド(バッチ&ストリーム) | ハイブリッド(バッチ&ストリーム) | ストリーム専用 | ストリーム専用 |
| 複雑なイベント処理 | サポート | サポート | サポート無し | サポート無し(開発者が直接処理する必要があります) |
| 遅延時間 | ストリーミング: 超低遅延(ミリ秒) | マイクロバッチ:ほぼリアルタイムの遅延(秒) | タプル単位: 非常に低い遅延時間(ミリ秒) | ログベース: 非常に低い遅延時間 (ミリ秒) |
| 配信保証 | バッチおよびストリーム処理に対して正確に1回の処理を保証 | バッチ処理に対して正確に1回、ストリーム処理に対して少なくとも1回の処理を保証 | 構成に応じて最小1回または最大1回の処理を保証 | 正確に1回の処理を保証(Kafka Streams、RocksDB) |
| 状態管理 | 様々な状態バックエンドとセマンティクスを持つ状態記憶操作の豊富なサポート | mapWithStateおよびupdateStateByKey状態記憶操作の関数の限定的なサポート | 状態記憶操作のネイティブサポートなし、外部データベースまたはTrident APIに依存 | 状態記憶操作のネイティブサポートなし、外部データベースまたはKafka Streams APIに依存 |
| 耐障害性 | チェックポイントと状態スナップショットを外部ストレージシステムに保存し、高可用性と迅速な障害復旧を提供。 部分的な障害に対するローカルリカバリをサポート。 | チェックポイントと事前ログを外部ストレージシステムに保存することで、フォールトトレランスを提供。 また、信頼できる分散データセット(RDD)から失われたデータを再計算するために系統情報を使用。 | 確認と再試行を使用して、信頼性の高いメッセージ配信を保証することでフォールトトレランスを提供。 | ZooKeeperを使用してログパーティションを複数のブローカーに複製し、クラスターのメタデータを保存することで、フォールトトレランスを実現。また、トランザクションと等価性プロデューサーを使用して、一貫性のある出力を保証します。 |
私たちがストリーム処理のための主な要素の中で優先的に考慮したのは、配信保証でした。 学習に使用するデータが欠落したり重複すると、データが偏ったり歪んで誤った学習が行われる可能性があるため、これを防止するために正確に一度(exactly-once)の配信保証をサポートする必要があり、これをサポートするのがFlinkとKafkaでした。
同じ理由で、Sparkの場合、バッチ方式では正確に一回を保証しますが、ストリーム方式では最低一回を保証して除外しました。
実際、FlinkとKafkaを検討する時点である程度Flinkを採用することになりました。
理由は、FlinkとKafkaの両方とも遅延時間や状態管理、耐障害性を備えていますが、Kafkaの場合、他社製品と統合が難しいため、Kafkaに依存する状況が発生する可能性が高く、メッセージブローカーとしてRabbitMQを使わなければならない状況だったからです。
それでも、FlinkとKafka(streams)を活用度の面でもう少し比較してみると、次のようになります。
| Flink | Spark | |
| 性能 | 大規模なストリーミングアプリケーションの高スループット、低遅延シナリオでの優れたパフォーマンス | Kafkaエコシステム内で効率的な処理を提供し、リアルタイム分析や中程度の作業負荷に最適 |
| 使い勝手の良さ | 経験豊富なユーザー向けに豊富な機能と豊富なドキュメントを提供 | Kafkaに精通しているユーザーには、統合とシンプルな操作性を提供 |
| エコシステム支援 | 様々なストリーミング要件に対応するための広範な統合とツールを備えた広範で活発なコミュニティを持つ | Kafkaエコシステム内での強力な統合とサポート |
| ユースケース | 複雑なイベント処理、大規模なアプリケーション、高度なストリーミング機能を必要とするシナリオに最適 | 中規模のストリーム処理やリアルタイム分析など、Kafkaと緊密に統合されたアプリケーションに |
| プログラミングの柔軟性 | 様々なプログラミング言語をサポート、PyFlink、Table APIなどのAPI抽象化を提供 | 主にJavaに重点を置き、他のプログラミング言語のサポートは限定的 |
Kafkaは、Kafkaエコシステム内で他の特化した機能を実行するものを簡単な設定と構成で簡単かつ迅速に統合することができますが、Kafkaをメインに使用しないシステムでは制限があります。
一方、Flinkはより柔軟に他のシステムと組み合わせることができるという特徴があります。
結果的に、この点を総合的に考慮し、最終的にFlinkを採用することになりました。
では、Flinkはどのようにデータを処理するのでしょうか?
Flinkの基本的なデータ処理構造は、Source Operator、Transform Operator、そしてSink Operator Operatorで構成されています。
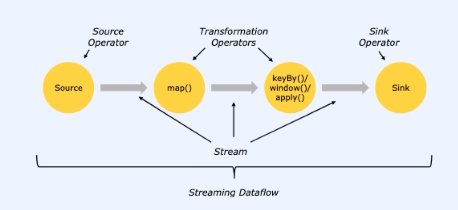
- 1. Source Operator
-
Source Operatorはデータストリームの入力を担当します。このオペレータは、外部システム(データベース、メッセージキュー、ファイルシステムなど)からデータを読み取り、Flinkのデータパイプラインに取り込みます。
Source Operatorは連続的なデータストリームを生成することも、定期的にデータをポーリングしてストリームを生成することもできます。 - 2. Transform Operator
-
Transform Operatorは、収集されたデータに対して、フィルタリング、集約、結合、ウィンドウイングなどの様々な前処理を行います。
データがFlinkを流れると、Transform Operatorはユーザー定義の演算を行い、データストリームの各要素を変換したり、情報を抽出します。 - 3. Sink Operator
-
Sink Operatorは、処理されたデータストリームを外部システムに出力します。このオペレータは、データをファイルシステム、データベース、または他のストリーム処理システムに送信することができます。
Sinkはデータの最終目的地であり、Flinkでのデータ処理が完了した後、外部システムでデータを使用できるようにします。
Time Series DB
最後に、データを保存する部分が残りました。 私たちはTime Series DB(以下、TSDB)を選択しました。
その理由は、EdgeCrossのIoTセンサーから収集されるデータが時系列の形だったからです。
TSDBは一般的なリレーショナルデータベースよりも時系列データを管理することに特に強みを持っています
TSDBは時系列データを効率的に扱うために考案されたデータベースで、書き込み性能に最適化されています。
リレーショナルデータベース(RDB)は、インデックスがかかっているとデータの量が大きくなるにつれて書き込み性能はどんどん低下しますが、TSDBのインデックスはこのような場合にも性能が落ちないように作られています。
TSDBは時間によって保存スペースを分離して、時間でクエリをすることができます。
私たちはここでInfluxDBを使いました。InfluxDBは2013年にGo言語で開発されたオープンソースのTime Series Database(以下TSDB)です。InfluxDBの場合、インデキシング性能が優れており、大容量データでも高速検索が可能で、データスキーマを柔軟に変更できるため、多様なデータ形態を簡単に処理することができます。
また、プラグインアーキテクチャー設計でサードパーティ製品との統合が容易で、公式文書がよく管理されており、実際にも多く知られており、参考となる事例などが多いという点もメリットです。
InfluxDBの特徴
InfluxDBの主な特徴としては、連続的なクエリと保存ポリシーがあります。連続的なクエリは、指定されたクエリを周期的に実行してデータを分析し、結果を新しいシリーズとして保存する機能を実行します。例えば、リアルタイムデータフィードから一定時間間隔で平均を計算したり、データをダウンサンプリングする作業を自動的に行うことができます。
保存ポリシーの場合、古いデータを自動的に削除するポリシーとして、データベース単位で定義されます。一つのデータベースに複数の保存ポリシーを持つことができます。データが継続的に蓄積されると、保存スペースや処理速度などの問題が発生する可能性があるため、このような機能をサポートしています。
内部構成
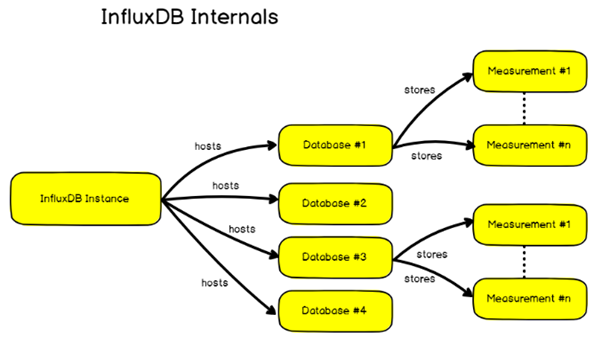
時系列データベースでmeasurementはRDBのtableに相当し、RDBと同じように一つのデータベースの中に複数のmeasurementがあることができます。
しかし、RDBとは少し違う概念があるのですが、influxDBはNoSQLの概念をベースに作られてSchemaless(スキーマがない)という点です。
固定されたスキーマを構成する必要がないので、時間が経つにつれてデータ構造が変更されても簡単に対応することができます。
まとめ
ここまで、EdgeCrossでデータパイプラインシステムをどのように実装したかをご紹介しました。
データパイプラインの構築方法に正解はありませんが、AIoTデバイスを中心にAIサービスを実装する企業では、どのようにデータパイプラインを構成したかを参考にしていただければと思います。
ありがとうございました。
EdgeCross公式ホームページはこちら






